
Introduction
This post is about setting up Spark to run on a Jupyter Notebook on a computer running Windows 10.
To follow along with this post, you should already have Java (JDK 8), Spark, Python, and Jupyter Notebook installed on your machine.
If you need help with those things, here are some helpful links:
How to Install Java (JDK 8)
How to Install Spark
How to Install Anaconda (Python & Jupyter Notebook)
What is Jupyter Notebook?
An open-source web app that can run code. Code is written in cells that are individually executed. Developers can execute a specific block of code without having to execute code from the start of the script.
PySpark
Open a Jupyter Notebook and select Python kernel
cmd> jupyter notebook

Execute Spark code!
1 2 3 4 5 6 | import findspark
findspark.init()
import pyspark
sc = pyspark.SparkContext(appName = "myApp")
a = sc.parallelize(range(10))
a.collect()
|
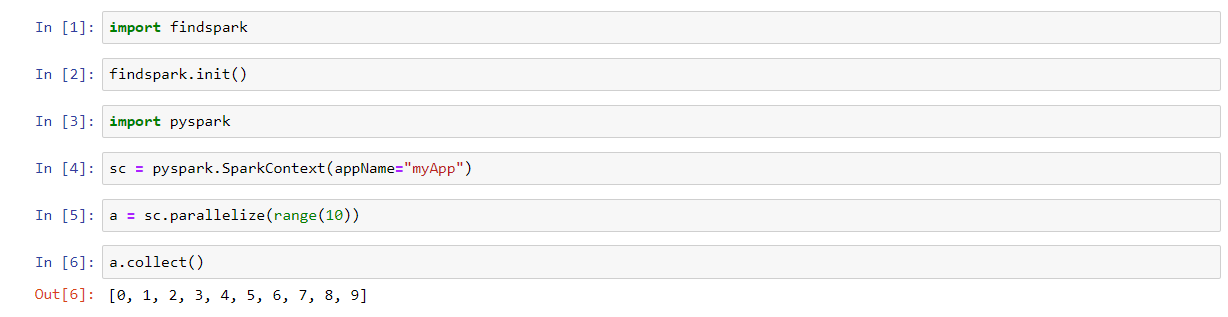
Note - I tried doing this using Spark 2.4 and encountered the following
error: Python worker failed to connect back. I switched to Spark 2.3.2 and
was able to execute Spark code with no errors.
Spark - Scala
This step is to if you want to develop in Spark using Scala.
Install spylon-kernel using pip
Type the following in a command prompt:
cmd> pip install spylon-kernel
Create a kernel spec
This allows us to select a Scala kerenel in a Jupyter Notebook.
cmd> python -m spylon_kernel install
Open a Jupyter Notebook and select spylon-kernel.

Execute Spark code!
1 2 | val a = sc.parallelize(1 to 9)
a.collect()
|
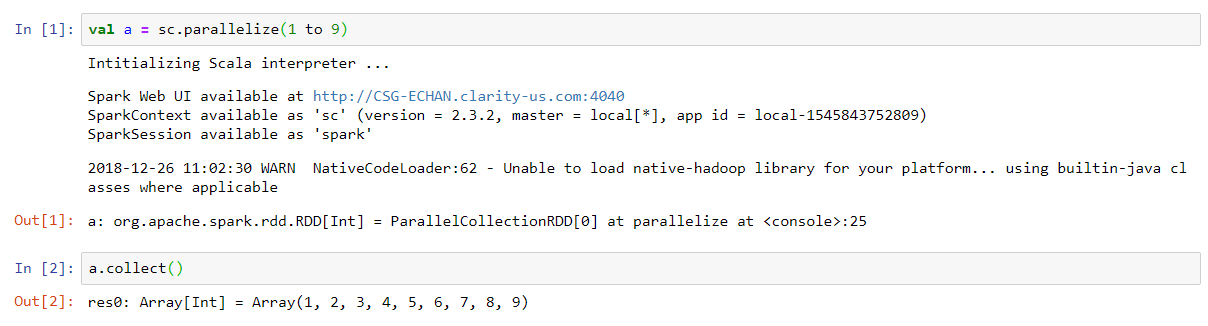
Note - I get a warning Unable to load native-hadoop library for your platform...using
builtin-java classes where applicable. This will be an issue if you connect to
a Hadoop cluster with Kerberos authentication but for our purposes, we can
ignore this.
Happy developing!