
Introduction
This post is about installing Spark on a computer running Windows 10.
If you want to run PySpark, you must have Python installed on your machine. If
you need help with that, refer to this:
How to Install Anaconda (Python)
If you only want install Spark (Scala), you can proceed to the installation.
Step 1 - Install Java
Java Development Kit 8 (JDK 8) is already installed
If JDK 8 is already installed on your machine skip to step 2.
How do I check if JDK 8 is installed on my machine?
Open a windows command prompt and type the following:
cmd> java -version
If you get the following output:
java version "1.8.0_191"
then JDK 8 is installed on your machine. The first two numbers are the important ones. The numbers after 1.8 are the build number and may vary depending on your build.
If you get an error, or a different version is installed, I recommend that you download and install JDK 8.
Java Development Kit 8 (JDK 8) is not installed
Step 2
Download Spark
Download & Install Spark. I chose Spark version 2.3.2 and package type for Hadoop 2.7 and later.
Note - I did not choose Spark versions newer than 2.3.2 because I received a
Python worker failed to connect back error when using PySpark. Spark 2.3.2
ran PySpark with no errors.
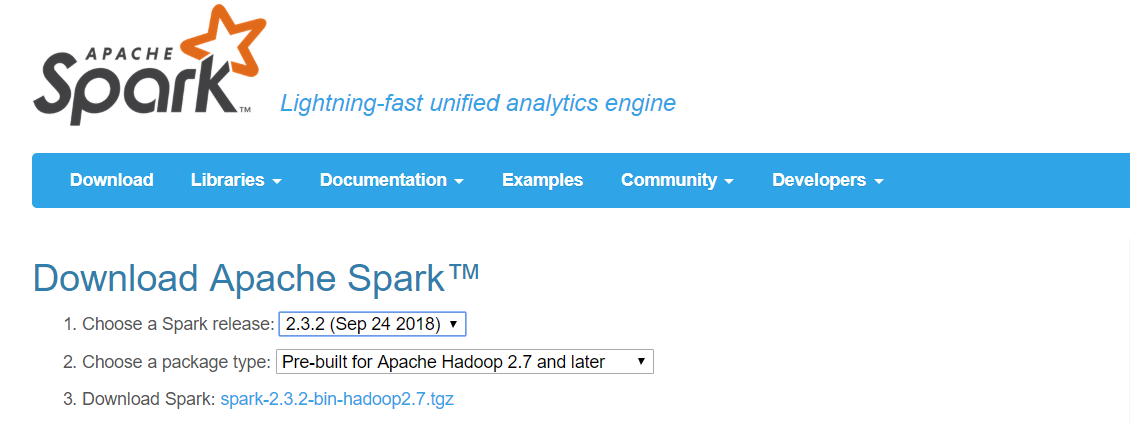 Spark Download Page
Spark Download Page
Set SPARK_HOME and add to PATH
Find where Spark was downloaded and extracted on your computer. Spark was
downloaded and extracted to my Downloads directory. SPARK_HOME needs to
point to your root Spark directory. The PATH should contain SPARK_HOME\bin.
I used the following to set my SPARK_HOME environment variable and add
SPARK_HOME to my PATH
cmd> setx SPARK_HOME "C:\Users\echan\Downloads\spark-2.3.2-bin-hadoop2.7"
cmd> setx PATH "%SPARK_HOME%\bin;%PATH%"
Close your command prompt and reopen a new one to refresh your environment
variables. Verify that your SPARK_HOME and PATH were set correctly.
cmd> echo %JAVA_HOME%
// to pretty print PATH
cmd> for %a in ("%path:;=";"%") do @echo %~a
You should see something like the following output:
C:\Users\echan\Downloads\spark-2.3.2-bin-hadoop2.7
// this should appear somewhere in your PATH
C:\Users\echan\Downloads\spark-2.3.2-bin-hadoop2.7\bin
Step 3
Download winutils
Download winutils.exe. Choose the
winutils version corresponding to your package type (I used hadoop-2.7.1).
Navigate to the hadoop-2.7.1/bin directory and download the winutils.exe
file. Move this file to your %SPARK_HOME%/bin directory.
Set HADOOP_HOME
Set your HADOOP_HOME environment variable to your Spark root directory.
cmd> setx HADOOP_HOME "C:\Users\echan\Downloads\spark-2.3.2-bin-hadoop2.7"
Restart your command prompt and verify that your environment were set.
cmd> echo %HADOOP_HOME%
You should see something like the following output:
C:\Users\echan\Downloads\spark-2.3.2-bin-hadoop2.7
Create hive directory
The Hive directory is used to store tables in Spark.
cmb> mkdir C:\tmp\hive
Add permissions to the hive directory
Using winutils.exe add full permissions to the \tmp\hive directory
cmd> %HADOOP_HOME%\bin\winutils.exe chmod 777 /tmp/hive
Start PySpark and execute Spark code
From the command prompt:
cmd> pyspark
In PySpark Shell:
1 2 | >>> a = sc.parallelize(range(10))
>>> a.collect()
|
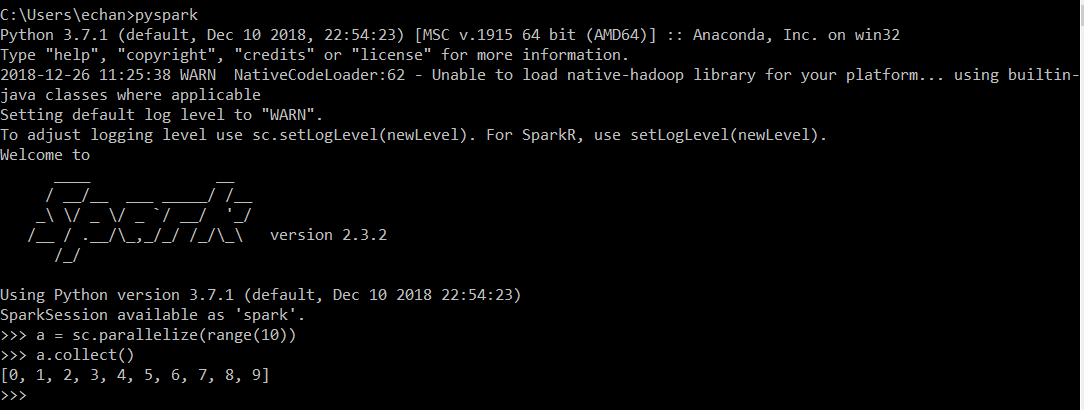
Note - I get a warning Unable to load native-hadoop library for your platform...using
builtin-java classes where applicable. This will be an issue if you connect to
a Hadoop cluster with Kerberos authentication but for our purposes, we can
ignore this.
Start Spark (Scala) and execute Spark code
From the command prompt:
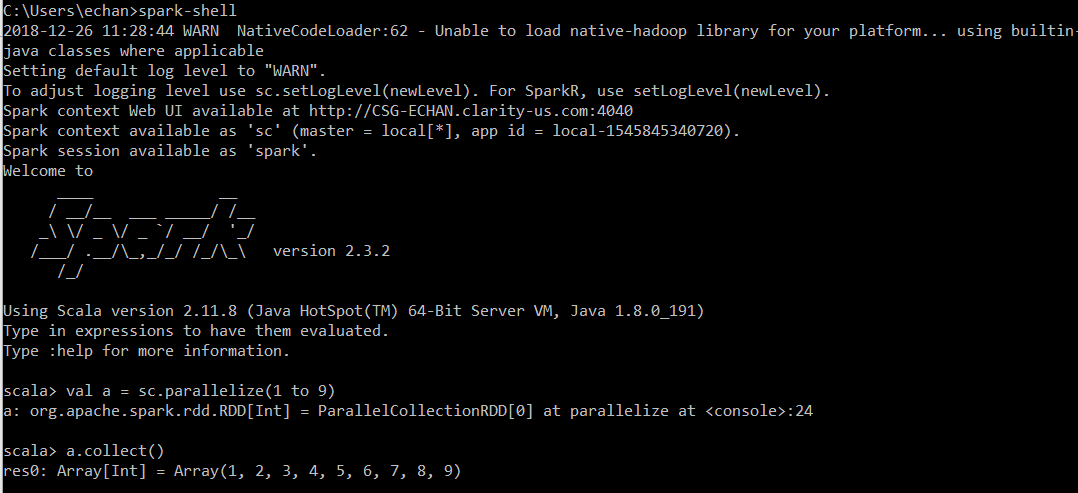
cmd> spark-shell
In Spark Shell:
1 2 | scala> val a = sc.parallelize(1 to 9)
scala> a.collect()
|
Happy developing!